本文共 4456 字,大约阅读时间需要 14 分钟。
Python中JSON解析
Python2.6开始加入了JSON模块。
Python的JSON模块序列化和反序列化分别是encoding和decoding。- encoding :将一个Python对象编码成JSON字符串。
- decoding:将JSON格式字符串解码成Python对象。
对简单的数据类型可以直接处理。如:string、unicode、int、float、list、tuple、dict
json模块编码
这里我们使用json.dumps()方法将一个Python数据类型列表编码(encoding)成为json格式的字符串。如:
>>> import json>>> data = [{ 'a':"A",'b':(2,4),'c':3.0}]>>> print "data :", repr(data)data : [{ 'a': 'A', 'c': 3.0, 'b': (2, 4)}]>>> data_json = json.dumps(data)>>> print data_json[{ "a": "A", "c": 3.0, "b": [2, 4]}] repr()是将一个对象转成字符串显示,注意只是显示用,有些对象直接转字符串会出错。如list,dict使用str()是无效的,但使用repr可以,这是为了看它们都有哪些值。
观察两次打印的结果,会发现Python对象转成JSON字符串以后,会有些变化,原元组被改成了json的数组。
在json的编码过程中,会存在从Python原始类型转化json类型的过程,但这两种语言的类型存在一些差异,对照表如下: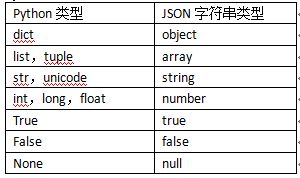
#对比实例>>> a = [{ 1:12, 'a':12.3}, [1,2,3], (1,2), 'asd', u'ad', 12, 13L, 3.3, True, False, None]>>> print json.dumps(a)[{ "a": 12.3, "1": 12}, [1, 2, 3], [1, 2], "asd", "ad", 12, 13, 3.3, true, false,null] 特别注意:编码以后,原字典key中非字符串类型变成了字符串类型。
json.dumps()
函数原型:
dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding='utf-8', default=None, sort_keys=False, **kw)
dumps函数的参数很多,但是不是每个都必须弄清楚的,下面只说明几个比较常用的参数吧。
sort_keys :是否按字典排序(a到z)输出。因为默认编码成json格式字符串后,是紧凑输出,并且也没有顺序的,不利于可读。>>> data = [ { 'a':'A', 'b':(2, 4), 'c':3.0 }]>>> print json.dumps(data)[{ "a": "A", "c": 3.0, "b": [2, 4]}]>>> print json.dumps(data, sort_keys=True)[{ "a": "A", "b": [2, 4], "c": 3.0}] indent :设置参数缩进显示的空格数。缩进显示使读起来更加清晰。
>>> data = [{ "a": "A", "b": [2, 4], "c": 3.0}]>>> print json.dumps(data, sort_keys=True, indent=3)[ { "a": "A", "b": [ 2, 4 ], "c": 3.0 }] separators :参数的作用是去掉,和:后面的空格,从上面的输出结果都能看到”, :”后面都有个空格,这都是为了美化输出结果的作用,但是在我们传输数据的过程中,越精简越好,冗余的东西全部去掉,因此就可以加上separators参数。
>>> print len(json.dumps(data))35>>> print len(json.dumps(data, separators=(',',':')))29 skipkeys :在encoding过程中,dict对象的key只可以是基本数据类型(str,unicode,int,long,float,bool,None),如果是其他类型,那么在编码过程中就会抛出ValueError的异常。skipkeys可以跳过那些非string对象的key的处理,就是不处理。
>>> data= [ { 'a':'A', 'b':(2, 4), 'c':3.0, (1,2):'D tuple' } ]>>> print json.dumps(data) #skipkeys参数默认为False时Traceback (most recent call last): File " ", line 1, in File "C:\Python27\lib\json\__init__.py", line 243, in dumps return _default_encoder.encode(obj) File "C:\Python27\lib\json\encoder.py", line 207, in encode chunks = self.iterencode(o, _one_shot=True) File "C:\Python27\lib\json\encoder.py", line 270, in iterencode return _iterencode(o, 0)TypeError: keys must be a string>>> print json.dumps(data, skipkeys=True)# skipkeys=True时[{ "a": "A", "c": 3.0, "b": [2, 4]}] ensure_ascii :表示编码使用的字符集,默认是是True,表示使用ascii码进行编码。如果设置为False,就会以Unicode进行编码。由于解码json字符串时返回的就是Unicode字符串,所以可以直接操作Unicode字符,然后直接编码Unicode字符串,这样会简单些。
json模块解码
将JSON格式字符串解码成Python对象,我们使用的是json.loads()函数,可以将简单数据类型decoding(解码)成Python对象。如:
import jsondata = [{'a':"Aasdf",'b':(2,4),'c':3.0}]data1 = [{ "name" : "ruby", "age" : 20, "address" : "BJ"}]data_json = json.dumps(data)print "encoding :", data_jsonprint "decoding :", json.loads(data_json) 执行结果:
encoding : [{ "a": "Aasdf", "c": 3.0, "b": [2, 4]}]decoding : [{ u'a': u'Aasdf', u'c': 3.0, u'b': [2, 4]}] 编码过程中,Python中的list和tuple都被转化成json的数组,而解码后,json的数组最终被转化成Python的list的,无论是原来是list还是tuple。
从json到Python的类型转化对照表如下:
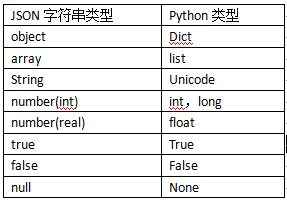
>>> a = [{ 1:12, 'a':12.3}, [1,2,3], (1,2), 'asd', u'ad', 12, 13L, 3.3, True, False, None]#编码后>>> print json.dumps(a)[{ "a": 12.3, "1": 12}, [1, 2, 3], [1, 2], "asd", "ad", 12, 13, 3.3, true, false,null]#解码后>>> print json.loads(json.dumps(a))[{ u'a': 12.3, u'1': 12}, [1, 2, 3], [1, 2], u'asd', u'ad', 12, 13, 3.3, True, False, None] 特别注意:
json格式的字符串解码成Python对象以后,String类型都变成了Unicode类型,数组变成了list,不会回到原元组类型,字典key字符也被转成Unicode类型了。 以上都是对简单数据类型的编码与解码,但是在实际的工作中,我们可能会遇到字典key或list中数据是类类型的,这个情况怎么进行序列化呢?将类的信息转换成json串
让我们看一个实例:
#coding=utf-8import jsonimport reclass C(object): def __init__(self): self.f4= 5class B(object): def __init__(self): self.f3 = 1 self.c = C()class A(object): def __init__(self): self.f1 = 1 self.f2 = "2" self.b = B() def func1(self):passa=A()def convert(a): seqDict={} for k,v in a.__dict__.items(): if re.match(r' 执行结果:
{ 'f1': 1, 'f2': '2', 'b': { 'c': { 'f4': 5}, 'f3': 1}}{ "f1": 1, "f2": "2", "b": { "c": { "f4": 5}, "f3": 1}} 这里有一个小技巧,就是对于是类类型的数据,用type()函数查看其类型是,返回的是<class '__main__.C'> 这种形式的,所以在convert()函数中,一旦碰到这种情况,就递归调用convert()函数本身再去处理类里面的内容,直到type()函数返回的类型是基本数据类型为止。